
El término síntesis de texto a voz (TTS) se refiere a la transformación artificial de texto en audio, algo como lo que las personas hacemos cuando leemos pero aplicado a los sistemas informáticos. Aunque TTS se ha vuelto muy común, los expertos en ciberseguridad del Instituto Internacional de Seguridad Cibernética (IICS) afirman que aún faltan por descubrir muchas implementaciones para esta tecnología, muchas de ellas potencialmente perjudiciales.
Los investigadores aseguran que es posible emplear herramientas avanzadas de aprendizaje automático para clonar la voz de un usuario en específico, lo que no necesariamente es algo bueno. Es por ello que, como de costumbre, le recordamos que este material fue elaborado con fines informativos, por lo que IICS no es responsable del mal uso que pueda darse a la información aquí contenida.
El uso de estas herramientas solía ser un problema, aseguran los expertos en ciberseguridad, ya que se requería de la recopilación de un conjunto enorme de muestras de voz y texto para un mejor resultado. No obstante, recientes investigaciones aseguran que es posible emplear inteligencia artificial para que una computadora emita el sonido deseado, algo que Google bautizó como Voice Cloning.
¿Clonación de voz?
Los expertos en ciberseguridad mencionan que es claro que una computadora podría imitar cualquier voz siempre y cuando se le proporcione la información necesaria. Los investigadores diseñaron el sistema de clonación de voz para que fuera capaz de obtener información desde dos fuentes: el texto que deseamos transformar a voz y una simple muestra de la voz que queremos escuchar.
Los investigadores ponen como ejemplo un escenario específico: “Imagine que deseamos que Batman diga la frase ‘Me gusta la pizza’; debemos retroalimentar al sistema con dicha frase en texto y un pequeño fragmento de la voz de Batman. Esta información debería ser suficiente para obtener el resultado deseado.”
Después de entender esta premisa, podemos dividir el proceso de clonación de voz en tres etapas distintas:
- Codificar la forma de onda de la voz en una representación vectorial de dimensión fija
- Codificar el texto deseado en una representación vectorial, combinar los dos vectores y decodificarlos en un espectrograma
- Utilizar un codificador de voz para transformar el espectrograma en una forma de onda de audio

Estos sistemas se han convertido en uno de los más importantes avances del deep learning, por lo que los expertos en ciberseguridad no se muestran sorprendidos ante la posibilidad de clonar completamente la voz de una persona a partir de una simple llamada telefónica, nota de voz en WhatsApp o cualquier otro medio para registrar una voz.
Por si fuera poco, existen varias soluciones de código abierto para concretar un proyecto de estas características. A continuación, los expertos en ciberseguridad le mostrarán cómo llevar a cabo este proceso:
- Comience por clonar este repositorio:
git clone https://github.com/CorentinJ/Real-Time-Voice-Cloning.git
- Instale las bibliotecas necesarias; este paso requiere contar con Python 3:
pip3 install -r requirements.txt
- En el archivo README también encontrará vínculos para descargar modelos y conjuntos de datos previamente entrenados para realizar una prueba antes de comenzar con el verdadero trabajo
- Finalmente, puede abrir la GUI ejecutando el siguiente comando:
python demo_toolbox.py -d <datasets_root>
A continuación se muestra una captura de pantalla con la respuesta arrojada por la herramienta:
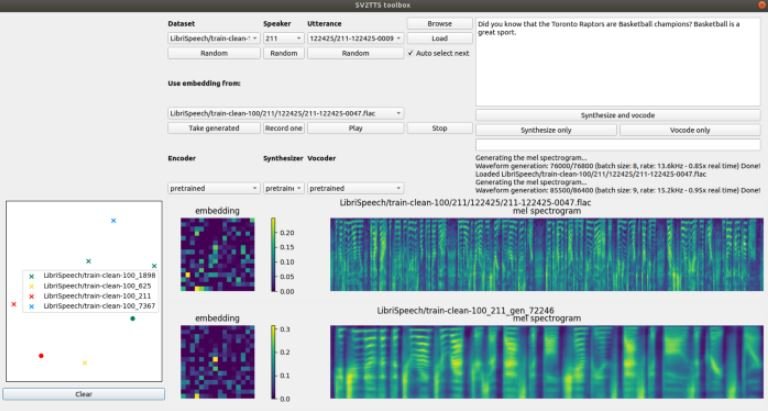
Como puede ver, se ha configurado el texto deseado en la herramienta: “¿Sabías que los Toronto Raptors son campeones de baloncesto? El baloncesto es un gran deporte”.
Puede hacer clic en la opción Random debajo de cada sección para aleatorizar la entrada de voz, luego haga clic en “Cargar” para ingresar la muestra de la voz que deseamos clonar.
La opción Dataset selecciona el conjunto de datos del que ingresarán las muestras de voz, mientras que Speaker selecciona a la persona que está hablando y Utterance selecciona la frase ingresada en texto. Para escuchar el resultado final, solo haga clic en Play.
Una vez que presione la opción Synthesize & vocode, el algoritmo se ejecutará. La herramienta incluso permite a los usuarios grabar su propia voz como entrada, mencionan los expertos en ciberseguridad.
Para conocer más sobre riesgos de seguridad informática, malware, vulnerabilidades y tecnologías de la información, no dude en ingresar al sitio web del Instituto Internacional de Seguridad Cibernética (IICS).








Trabajando como arquitecto de soluciones de ciberseguridad, Alisa se enfoca en la protección de datos y la seguridad de datos empresariales. Antes de unirse a nosotros, ocupó varios puestos de investigador de ciberseguridad dentro de una variedad de empresas de seguridad cibernética. También tiene experiencia en diferentes industrias como finanzas, salud médica y reconocimiento facial.
Envía tips de noticias a info@noticiasseguridad.com o www.instagram.com/iicsorg/
También puedes encontrarnos en Telegram www.t.me/noticiasciberseguridad

