
Una araña web, es una herramienta que examina páginas Web, de forma ordenada y automatizada. Los buscadores de Internet suele usan estas herramientas a modo de bots, para crear una copia de la página web, para su posterior procesado e indexado, consiguiendo así búsquedas más rápidas.
Las arañas web identifica los hiperenlaces de la página y los agrega a la lista de URLs a visitar, de forma recurrente dependiendo de el conjunto de reglas que se han definido en su configuración, como puede ser restringir la búsqueda a un dominio. La araña descarga estas direcciones y algunos tipos de arañas también descarga los archivos que contiene el sitio Web.
Con ese archivos que recoge la araña web se pueden usar técnicas de extración de metadatos. Los metadatos, es la información insertada en los archivos por el software de edición o creación de los mismos, estés metadatos contienen información acerca de la creación del archivo como: nombre de autor, autores anteriores, nombre de compañía, cantidad de veces que el documento fue modificado, fecha de creación…
Los metadatos pueden tener varias aplicaciones como:
En informática forense: Para demostrar en un juicio que unos archivos de imágenes pertenecen a una determinada cámara de fotos.
En ataques a sistemas o servidores web: Atreves de los metadatos podemos obtener los nombres de posibles usuarios, sistema operativo, nombres de red… para después realizar un ataque de fuerza bruta.
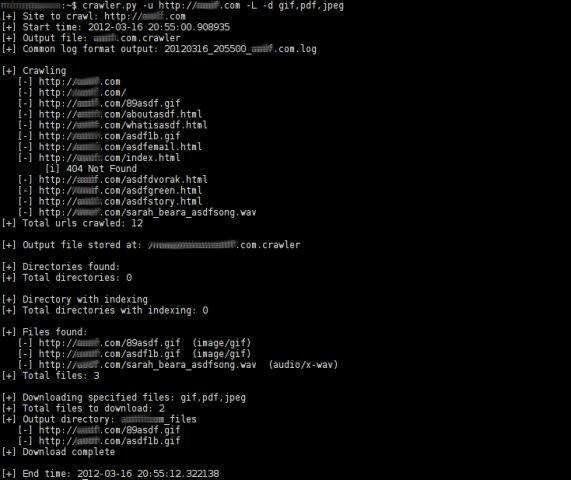
Un ejemplo es Web Crawler una araña Web basada en Python, orientado a ayudar en las tareas de test de penetración. La tarea principal de esta herramienta es la búsqueda y la lista de todos los enlaces páginas y archivos en un sitio web.
Entre las características de Web Crawler destaca:
Analiza sitios Web en Http y Https, incluso si no utilizan los puertos comunes de estés protocolos.
Permite determinar la profundidad del rastreo.
Genera un resumen al final del rastreo con estadísticas sobre los resultados.
Implementa método HEAD para el análisis de los tipos de archivos antes de descargarlos. Esta característica mejora la velocidad de manera significativa.
Utiliza expresiones regulares para encontrar enlaces ‘href’, ‘src’ y ‘content’.
Identifica vínculos relativos.
Identifica archivos no html y los muestra.
Identifica la indexación de directorios.
Permite exportaciones en un archivo separado con una lista de todas las URL de archivos encontrados durante el rastreo.
Permite seleccionar el tipo de archivos para descargar. Guarde los archivos descargados en un directorio. Sólo crea el directorio de salida si hay al menos un archivo para descargar.
Genera un registro de salida en CLF de la solicitud realizada durante el rastreo.
Trata de detectar si el sitio utiliza un CMS como: WordPress, Joomla, etc
Busca archivos tipo: ‘.bk’ y ‘.bak’ de php, asp, aspx, jps…
Web Crawler posee la opción interactiva de descargar archivos generando una lista de exportación en un archivo. Con esta lista se pueden descargar archivos y analizarlos con un software para extracción de metadatos como: ExifTool y Metagoofil
ExifTool, la mejor herramienta para extraer metadatos de imágenes ya que puede trabajar con EXIF e IPTC (estándares utilizados por cámara de fotos para intercambiar ficheros de imágenes con compresión JPEG). Además reconoce metadatos insertados por cámaras: Canon, Casio, FujiFilm, HP, JVC/Victor, Kodak, Leaf, Minolta/Konica-Minolta, Nikon, Olympus/Epson, Panasonic/Leica, Pentax/Asahi, Ricoh, Sanyo, Sigma/Foveon y Sony. Disponible para Windows, Mac OSX y en modulo Perl lo que permite utilizarla en Linux.
Metagoofil, diseñada para extraer archivos: pdf, doc, xls y ppt de un sitio web a través de google, y analizar los metadatos de los archivos. Para obtener información y realizar un ataque o un test de intrusión.
También existe una herramienta llamada CeWL que integra las dos técnicas actúa como una araña Web y extrae los metadatos del sitio web a rastrear. Esta herramienta genera tres listas con la siguiente información:
Una lista de palabras de la Web que se pueden utilizar como contraseña para ataques de diccionario.
Una lista con direcciones de correo electrónico, de la que se puede extraer posibles usuarios.
Una lista con usuarios y autores extraídos de los metadatos de los archivos encontrados en el sitio Web, soporta archivos de formato Office hasta 2007 y PDF. Ideal para recabar lista de de nombres de usuarios.
CeWL es una herramienta para sistemas Linux escrita en Ruby ideal para auditar la seguridad de sitios Web, controlando la información que se proporciona en los metadatos. Como una primera toma de contacto esta bien, pero siempre es mas eficiente combinar los resultados de una araña Web con herramientas de extracción de metadatos.
Fuente:https://www.gurudelainformatica.es/







Trabajando como arquitecto de soluciones de ciberseguridad, Alisa se enfoca en la protección de datos y la seguridad de datos empresariales. Antes de unirse a nosotros, ocupó varios puestos de investigador de ciberseguridad dentro de una variedad de empresas de seguridad cibernética. También tiene experiencia en diferentes industrias como finanzas, salud médica y reconocimiento facial.
Envía tips de noticias a info@noticiasseguridad.com o www.instagram.com/iicsorg/
También puedes encontrarnos en Telegram www.t.me/noticiasciberseguridad

