
Open Source Intelligence (OSINT), o más precisamente, el uso de fuentes de inteligencia de código abierto para perfilar la exposición en Internet de las organizaciones es decir, footprinting, es una área un muy interesante dentro de la seguridad de la información, particularmente porque es más o menos abierta, lo que supone un problema en este momento.
Hay muchas cosas interesantes que se pueden hacer con datos que se pueden encontrar al aire libre. Por ejemplo, si se puede obtener una lista de bloques de IP que pertenecen a una organización para la que se está haciendo un test de penetración, se puede hacer un barrido y comprobar si hay hosts online. Otro ejemplo es que si puede obtener una lista de direcciones de correo electrónico que pertenecen a una organización, puede repetir y verificar cada dirección de correo electrónico con un servicio como “HaveIBeenPwned” para encontrar varias cuentas que pertenecen al personal de la organización objetivo, que podría haber sido comprometido antes.
Una cosa a tener en cuenta acerca de la inteligencia de código abierto es que no es solo una práctica para el descubrimiento de activos y tampoco es una práctica que se restringe por completo a la seguridad de la información. Personalmente lo describiría como una práctica de recopilar información pública de varias fuentes, en la que se analiza la información recopilada para crear un modelo que pueda usarse para tomar decisiones. Las empresas y los inversores también hacen uso de la inteligencia de código abierto para realizar análisis competitivos y de mercado, entre otras cosas.
Uso defensivo: pronóstico de amenazas.
Diría que una posible aplicación defensiva de OSINT es la predicción de amenazas. Es posible hacer esto monitorizando en varias plataformas en línea y verificando posibles vulnerabilidades para pronosticar amenazas potenciales contra su organización. Por ejemplo, puede controlar pérdidas de contraseña que podrían poner en riesgo una organización. Probablemente se necesite hacer algunos procesos bastante avanzadas que involucren el aprendizaje automático y el procesamiento del lenguaje natural. Si se planea automatizar esta práctica, porque inevitablemente se tendrá que ordenar mucha información no estructurada cuando se trata de conversaciones entre humanos. Si se va a construir un sistema automático de predicción de amenazas, probablemente se recopilara información sobre lo que constituye una amenaza primero y luego determinar qué tipo de métricas se pueden extraer de eso para tener algo que alimente un algoritmo de aprendizaje automático más adelante. Tal vez se pueda reunir un montón de publicaciones de Facebook y Twitter que amenazan una organización y luego crear una bolsa de palabras o un modelo que luego se pueda utilizar para entrenar a un clasificador Naive-Bayes para detectar otras publicaciones que amenazan una organización. Esto es similar a cómo funcionan los filtros de spam por cierto. Una vez que integre las métricas en un algoritmo de aprendizaje automático, se generará un clasificador que, a su vez, permitirá determinar automáticamente las amenazas en el futuro. Por supuesto, este clasificador no será completamente preciso y deberá corregirse con datos adicionales a medida que el sistema se vuelva más maduro.
Alternativamente, puede optar por un tipo de sistema de puntuación enfático . En este enfoque, intenta determinar una amenaza en un mensaje en función de las palabras que contiene. Digamos que eres un fabricante de cereales y hay alguna charla en línea sobre ti que contiene las palabras “explotar” o “vulnerabilidad” o “fuga” u otras palabras técnicas que no se combinan bien con los productos relacionados con el desayuno. Si ve algo así, eso podría indicar algún tipo de amenaza cibernética contra su organización.
Uso ofensivo: Footprinting.
En cuanto a las posibles aplicaciones ofensivas de OSINT: se puede usar para footprinting, como mencioné anteriormente en el párrafo inicial del post. Esto es útil en las fases de reconocimiento de un test de penetración, ya que puede aprovechar la información que proporciona el footprinting cuando se realiza otras tareas de reconocimiento, como el escaneo y la enumeración. Por ejemplo, como se describe en la sección de inicio de este artículo, se puede someter los rangos de direcciones IP que se encuentren a través de footprinting a escaneos de puertos para encontrar hosts online en las redes de destino. Los resultados de footprinting son bastante útiles en otras tareas de test de penetración no relacionadas con el reconocimiento, como cuando se realizan escaneos de vulnerabilidad y se realizan tareas de explotación. Esencialmente permiten tener un mapa de los activos de una organización objetivo, por lo tanto, se tiene una muy buena idea de dónde empezar a buscar vulnerabilidades.
La herramienta:
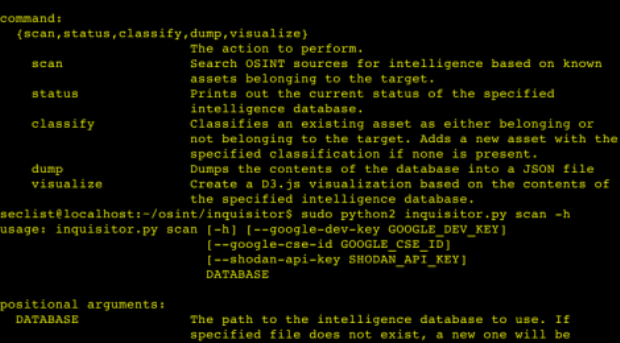
Inquisitor es una herramienta sencilla para recopilar información sobre empresas y organizaciones mediante el uso de fuentes de Open Source Intelligence (OSINT). Está inspirado en la forma en la que operan Maltego y Recon-ng, y prácticamente implementa de nuevo algunas de las características de esas herramientas, pero agrega una capa adicional de semántica basada en los tipos de activos para crear una solución fácil.
Las características principales de Inquisitor son:
- La capacidad de poner en cascada la etiqueta de propiedad de un activo (por ejemplo, si se sabe que un nombre de una persona que pertenece a la organización objetivo, los hosts y las redes registradas con ese nombre se marcarán como pertenecientes a la organización objetivo).
- La capacidad de transformar activos en otros activos potencialmente relacionados mediante la consulta de fuentes abiertas como Google y Shodan.
- La capacidad de visualizar las relaciones de esos activos a través de un diseño de paquete ampliable
Concepto:
El concepto completo de Inquisitor gira en torno a la idea de extraer información de fuentes abiertas en base a lo que ya se sabe sobre una organización objetivo. En el contexto de Inquisitor estos se llaman “transformaciones”. La información relacionada también se puede recuperar de forma inmediata de un activo conocido en base a metadatos que también se pueden recuperar de fuentes abiertas como whois y registros de Internet.
Flujo de trabajo:
Ahora que conoce las funciones básicas de Inquisitor, es hora de que aprender cómo usarlo realmente . Inquisitor se ha escrito teniendo en cuenta los siguientes pasos:
Siembra.
En este paso, la base de datos de inteligencia aún no tiene nada. La forma de comenzar el proceso es sembrar la base de datos con activos que se saben que pertenecen la organización objetivo. Se puede hacer esto usando el comando “classify”.
Exploración.
Ahora que la base de datos tiene activos que se sabe que pertenecen a la organización objetivo. Luego se puede continuar con el escaneo. Se puede hacer esto usando el comando de “scan”. Cuando invoca el comando “scan” en la base de datos de inteligencia, Inquisitor procede a ejecutar los métodos de transformación de los activos que se clasifican como aceptados. Una vez que finaliza el escaneo, terminará con más activos que podrían pertenecer a la organización objetivo. Si no termina con ningún activo nuevo, se puede inicializar la base de datos de inteligencia con nueva información, o simplemente continuar para finalizar el proceso siguiendo con el paso Informes.
Clasificado.
Si bien Inquisitor realiza una clasificación de activos automática para el usuario, es posible que falten algunos activos que, de hecho, pertenecen a la organización objetivo. Cuando esto sucede, se deberá verificar los contenidos de la base de datos y clasificar manualmente los activos. Por lo general, conviene prestar atención a los activos, ya que no hay manera de determinar automáticamente la propiedad de ese tipo de activos. Además, la mayoría de los otros tipos de activos dependen de la clasificación de propiedad de los activos del objetivo para determinar si pertenecen a su objetivo o no, por lo que es definitivamente mejor prestar atención a sus activos propios. Además, no se suele terminar con muchos activos de objetivos en primer lugar, por lo que no será tan difícil analizarlos.
Informes.
Puede generar una visualización de los activos que pertenecen a su organización objetivo utilizando el comando ”visualize” o el comando ”dump”.
Fuente:https://www.gurudelainformatica.es/2018/03/uso-defensivo-y-ofensivo-de-open-source.html








Entusiasta de la seguridad cibernética. Especialista en seguridad de la información, actualmente trabajando como especialista en infraestructura de riesgos e investigador.
Experiencia en procesos de riesgo y control, soporte de auditoría de seguridad, diseño y soporte de COB (continuidad del negocio), gestión de grupos de trabajo y estándares de seguridad de la información.
Envía tips de noticias a info@noticiasseguridad.com o www.instagram.com/iicsorg/.
También puedes encontrarnos en Telegram www.t.me/noticiasciberseguridad

