
¿Qué haces cuando necesitas encontrar algo en Internet? Buscarlo en Google. Es un acto reflejo, que realizamos sin pensar.
El término “googlear” está aceptado por la Real Academia Española, como sinónimo de buscar algo en Internet. Si no está en Google, no existe, ¿verdad? Lo cierto es que no.
De hecho, utilizando un conocido símil, si Internet es el mar Google es sólo un pequeño barco de pesca que tira sus redes y coge unos pocos peces del vasto océano.
No hay cifras oficiales, pero se estima que los buscadores comerciales como Google, Yahoo! o Bing apenas indexan el 5 o el 10% de Internet. El resto es lo que se conoce como “deep web“, la web profunda, o la Internet invisible, que no sale en los buscadores.
No hay que confundir con la dark net o dark web, que es donde se condensan las actividades ilegales: blanqueo de dinero con bitcoins, venta de drogas, hackeos ilegales, pornografía infantil… En la deep web hay mucho contenido ilegal, cierto, pero también muchas páginas útiles, científicas, educativas, y comerciales que no aparecen en los buscadores porque ellas mismas lo han pedido, o los propios buscadores no llegan hasta sus dominios.
Aquí es donde entra en juego el motor de búsqueda Memex, desarrollado por la DARPA, la Agencia americana de Proyectos de Investigación Avanzados de Defensa, la mismísima creadora de Internet. Memex será un buscador de la deep web creado para localizar el 100% de las páginas web de Internet.
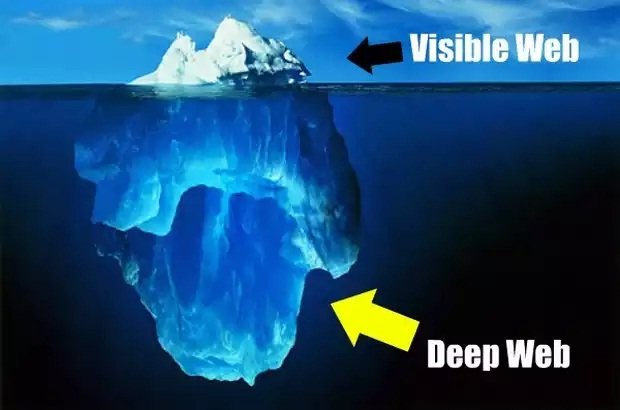
¿Por qué buscadores como Google, Bing o Yahoo! no indexan todas las páginas web que existen? Hay varias causas.
Por un lado, existen webs que no se registran para aparecer en los buscadores, o que piden expresamente no mostrarse en ellos. O que no se puede llegar hasta ellas siguiendo enlaces. Por otro, muchas páginas permanecen encriptadas a través de Tor, I2P y otros sistemas de ocultación y anonimización.
Finalmente, no hay perder de vista que Google, Bing, Yahoo! etc son buscadores comerciales. Se esfuerzan por localizar páginas bajo unos determinados estándares que puedan interesar masivamente a sus clientes, y que puedan contener su publicidad. Indexar webs oscuras, poco utilizadas que apenas van a traer tráfico o no contienen publicidad, no merece la pena el esfuerzo, desde un punto de vista comercial.
Pero el hecho de que las compañías con más recursos de Internet como Google, Microsoft o Facebook hayan dado la espalda a la deep web, es un arma de doble filo. Se trata de un territorio inexplorado del que se conoce muy poco, porque nadie ha dedicado recursos para analizarlo en profundidad. Hasta ahora.
La DARPA, la agencia de defensa americana que creó Internet en los años 60, anunció el año pasado que estaba trabajando en el Proyecto Memex, un buscador de la deep web que tiene como objetivo sacar a la luz lo que se esconde en los rincones más profundos y desconocidos de Internet.
Para ello va a contar con la ayuda de 17 compañías especializadas en diferentes áreas (no ha revelado sus nombres), que van a trabajar en diferentes módulos. El objetivo es desarrollar buena parte de esos módulos en código abierto, para que los buscadores convencionales puedan acceder también a la deep web.
El proyecto se está desarrollando en secreto, pero hace unas semanas se anunció que la compañía Hyperion Gray es una de las que está trabajando en uno de los módulos deproyecto Memex.

En una entrevista en Forbes, un representante de Hyperion Gray afirma que están utilizando tecnologías de scraping y web crawling (raspado y extracción de datos directamente de una web), con una dosis de Inteligencia Artificial y machine learning.
Está claro que para explorar la deep web, los métodos tradicionales de indexación no sirven.Memex empleará la inteligencia artificial y el machine learning (algoritmos que aprenden y mejoran por su cuenta a partir de los datos que recopilan) para analizar las búsquedas y los métodos de entrada que utilizan los usuarios de la deep web, e intentar llegar a los mismos lugares que ellos, pero con un bot automatizado.
Memex es un proyecto a medio plazo (necesita dos años más de desarrollo) y de momento, todo es bastante secreto. Pero el anuncio de los primeros módulos por parte de Hyperion Gray, y el hecho de que parte de su código podrá incorporarse a cualquier buscador, augura un cambio profundo en los resultados de los buscadores, en los próximos años.
El problema de sacar a la luz la deep web, es descubrir lo que allí te vas a encontrar… ¿Estamos preparado para ello?
Fuente:https://computerhoy.com/



Trabajando como arquitecto de soluciones de ciberseguridad, Alisa se enfoca en la protección de datos y la seguridad de datos empresariales. Antes de unirse a nosotros, ocupó varios puestos de investigador de ciberseguridad dentro de una variedad de empresas de seguridad cibernética. También tiene experiencia en diferentes industrias como finanzas, salud médica y reconocimiento facial.
Envía tips de noticias a info@noticiasseguridad.com o www.instagram.com/iicsorg/
También puedes encontrarnos en Telegram www.t.me/noticiasciberseguridad


