
De vez en cuando, encontramos comportamientos raros y extraños que no están relacionados con hacks de sitios web, pero que causan grandes problemas para propietarios de sitios web. Recientemente, escribimos acerca de una referencia de spam malicioso en Google Analytics y sobre un caso en que el Google Search Console fue utilizado por los atacantes después de obtener acceso a un sitio web.
Hoy vamos a ver cómo Googlebot dañó un sitio web después que limpiamos un gran spam. Si usted utiliza el Google Search Console / Herramientas para Webmasters de Google (y debería hacerlo) proporcionaremos instrucciones específicas para asegurarse de que no será afectado.
Indicadores de Compromiso (IoC)
Vamos a empezar analizando los señales de este tipo de infección masiva de spam que ha generado el problema con Googlebot.
- Esta infección crea miles de archivos de spam japonés en el sitio web, en la mayoría de los casos, JavaScript y HTML.
- Se modifica el Título y la Descripción en las páginas de resultados de búsqueda de Google.
- A menudo, impacta de repente la cuota de disco de su cuenta de hosting, debido al gran número de archivos creados.
Detalles de la Infección
Ahora, echemos un vistazo a cómo la campaña de spam japonés funciona:
- Los atacantes crean páginas de entrada en un sitio web infectado para que sean incluidas en el rango de resultados de Google para búsquedas relevantes.
- Cuando alguien que está haciendo una búsqueda hace clic en estos resultados, estas doorways redirigen a sitios web de terceros que los hackers quieren promover.
Aquí es donde todo se pone aún más interesante. Google sólo pondrá en el rango las páginas doorway si hay muchos enlaces que conducen a ellas. Esta es una de las formas por la cual Google identifica resultados de la búsqueda “buenos” como parte de su algoritmo.
Es difícil predecir que alguien podría poner links a páginas doorway, ya que sólo los hackers saben que ellas existen. Es por esta razón que los atacantes ponen links para sus sitios web en otras doorways de su propia creación en sitios web hackeados.
Sigue un ejemplo, usando el Unmaskparasites para descubrir uno de estos doorways y sus links externos que vienen de sitios web hackeados:
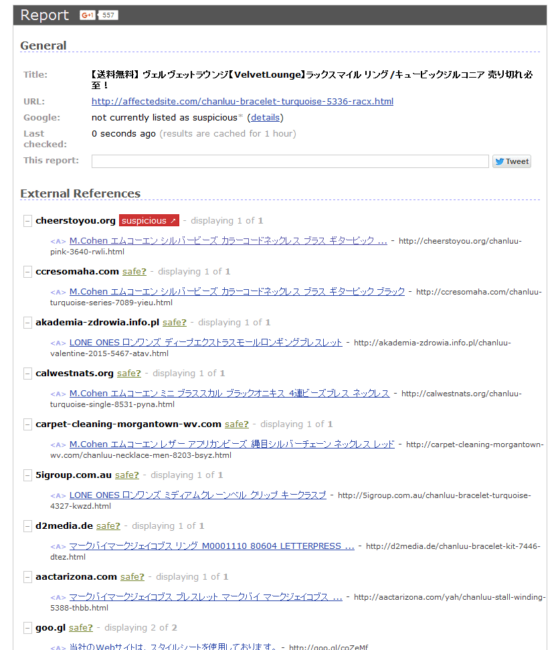
- Ahora, vamos a hacer los cálculos.
- Campañas de spam típicas infectan aproximadamente 3.000 sitios web.
- Cada sitio web, como sabemos, tiene, por lo menos, 25.000 páginas de spam/doorways (a menudo aún más que eso).
- Cada doorway tiene, por lo menos, 5 links para otros sitios web hackeados.
- Lo que genera, aproximadamente, 125.000 links enviados por sitio web hackeado.
- Como se distribuyen de manera uniforme entre todos los sitios comprometidos, esto significa que cada sitio web hackeado tiene aproximadamente 40 links a cualquier otro sitio web hackeado.
Esto significa que todos los sitios web hackeados, en conjunto, tienen alrededor demiles de 125.000 links para doorways en cada sitio web hackeado individualmente. Hasta este número está sobrevalorado, ya que los hackers suelen crear más de un directorio con archivos de spam, cada uno con más de 20.000 archivos de spam.
Como se puede ver, hay un gran número de links recibidos por su sitio web y Google también puede verlos.
El Impacto de un Spam en la Optimización del Motor de Búsqueda (SEO)
Ahora, vamos a entender cómo este problema de links recibidos afecta a su SEO y lo que sucede cuando usted los limpia:
- Como hemos calculado anteriormente, es probable que haya más de 125.000 referencias en la web que dirigen el spam a su sitio web, eso significa que el Googlebot los rastreará en otros sitios web infectados y comenzará a rastrear su sitio web en busca de estos links.
- Si el spam no se borra rápidamente, puede causar una fuerte caída en su posicionamiento de SEO , cuando se genera un gran número de doorways de spam que chupan su link juice y disminuyen su reputación.
- Después que Google borra todos estos archivos todavía intenta rastrearlos de vez en cuando, ya que los backlinks pueden estar en otros lugares. Esto puede generaruna gran cantidad de errores 404 en el panel de búsqueda de su Google Console (Herramientas para Webmasters).
Mitigación e Recuperación
Ahora, vamos a pensar en cómo mitigar este gran número de páginas de error 404 que Googlebot esperaba encontrar:
- Si usted quiere poner sus manos a la obra con un proceso que consume mucho tiempo, puede utilizar la herramienta URL Removal en el Search Console. Es un método muy eficiente cuando se trata de pocos links y los resultados aparecen rápidamente. Sin embargo, es difícil presentar todos los links de uno en uno. Google recomienda el uso de la solución robots.txt en algunos casos.
- Robots.txt es un archivo en el servidor que le dice a los bots cuáles partes de su sitio web deben ser rastreadas y cuáles no se deben rastrear. Como la mayoría de las páginas de spam están ubicadas en carpetas falsas como “fjhj”, “thg”, “gtg”, “iut”, haga clic en disallow bots (como Googlebot) para rastrear todas estas carpetas. Esto eliminará inmediatamente los errores 404 de estas páginas en el informe “Crawl Errors” en el Search Console, ya que el Googlebot no logrará ni siquiera hacer un intento de rastrearlas.
La Solución robots.txt
Básicamente, usted necesita crear un archivo robots.txt con el siguiente contenido y ponerlo en el directorio raíz de su sitio web:
User-agent: *
Disallow: /fjhj/
Disallow: /thg/
Disallow: /gtg/
Disallow: /iut/
Si no se toman medidas para mitigar estas páginas de errores 404, Google mostrará gradualmente más y más errores 404 “Not Found” cada día en su búsqueda en el Search Console, este número podría llegar a cientos de miles en un corto período de tiempo.
Googlebot Confuso
Vamos a hacer un análisis detallado sobre por qué Google muestra más páginas 404 después de la eliminación de un spam de un sitio web:
- Cuando los atacantes infectan su sitio web, todas las páginas de spam estaban allí, pero el Googlebot puede no haber encontrado ninguna referencia a ellas. Si ya hubiera encontrado, las páginas estarían allí, y no habría un error 404.
- Google no rastrea todas estas 100.000 nuevas páginas de spam a la vez. porque no quieren que su bot cause problemas de rendimiento para el servidor, entonces el Googlebot, en general, tiene una cuota en el número de páginas que puede rastrear todos los días, sobre todo si su sitio web no produce miles de URLs nuevas todos los días.
- Usted encontrará esta información en “Crawl Stats” en su Search Console. El número medio habilitado por defecto es un valor que se asigna automáticamente por el análisis que hace de respuesta de carga a la red de su sitio web. Google quiere mantener un número equilibrado de rastreos, para no afectar la velocidad de su sitio web.
- Lo mismo ocurrió en otros sitios web hackeados que envían links a sus páginas de spam. Con el tiempo, Google aumentó gradualmente el número de páginas de spam que rastrea a diario (y nuevos links para su sitio web).
- Google rastreará todos los links que estuvieren en sitios web externos que enlazan a su sitio web, entonces, incluso después de limpiar la infección, puede haber miles de links en la “cola” de Google para rastrear. También pueden encontrar links a otros sitios web infectados que todavía apuntan para las páginas de spam que fueron retiradas y serán añadidas a la “cola”, que en ese momento, aparecerá como un error 404.
- Finalmente, Google comienza a rastrear de nuevo los doorways en su sitio web y observará que ¡todos ellos desaparecieron! Esto hace que el número de errores 404 se acerquen al máximo. Google siempre trata de rastrear las páginas eliminadas, al menos algunas veces durante varias semanas para asegurarse de que realmente desaparecieron para siempre, antes de dejarlas fuera del índice, para probar que el 404 no es sólo un problema de mantenimiento temporal.
Es una práctica normal páginas de Google volver a visitar páginas 404 y sólo eliminarlas del índice después de algunos intentos de verificación fallidos. John Mueller (Analista Senior de Google Trends) habló sobre ese asunto hace algunos meses:
… sin embargo, de vez en cuando rastreamos de nuevo para asegurarse de que estas páginas desaparecieron en realidad , sobre todo cuando nos encontramos con un nuevo link dirigido a ellas.
Entonces, lo qué podemos decir es que, incluso si su sitio web ya está limpio, es posible que sufra a largo plazo con un efecto secundario: ver el Google intentar rastreas miles de páginas de spam no existentes por unas cuantas semanas después de la limpieza.
El DDoS Raro y Accidental Hecho por Googlebot
Ahora , vamos a mostrar algunos raros casos en que el performance analyzer automático de Google no logró ofrecer un resultado preciso de la frecuencia de rastreo “óptima”. Esto generalmente se debe a un problema de red temporal en el sitio web o el servidor y, en tales casos, Google comienza a rastrear su sitio web muy intensamente. Esto puede llegar a tomar su sitio web abajo, algo más o menos como un ataque DDoS muy intenso.
La Solución
En primer lugar, vaya a su Google Search Console (Herramientas par Webmasters) y siga estos pasos:

En esta pantalla, se puede ver algunas configuraciones, pero estamos interesado en las configuraciones del Crawl Rate.
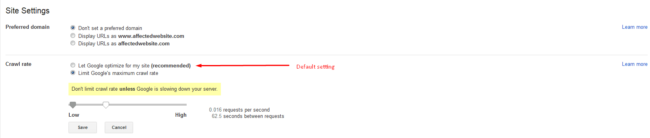
La primera opción es la configuración por defecto que su sitio web tiene tan pronto como se agrega un nuevo sitio web como su propiedad. Dado que ella no está funcionando bien para un sitio que ha sido infectado, utilizaremos una segunda opción.
La mejor configuración para la mayoría de los casos se encuentra justo antes de la mitad del control deslizante, pero todavía no es suficiente para conseguir un rendimiento decente para su sitio web, no dude en bajar un poco más para conseguir un rendimiento estable para su sitio web.
Tenga en cuenta que esta configuración sólo se debe cambiar si el sistema de rastreo de Google está en realidad ralentizando su sitio web, ya que este cambio puede hacer una gran diferencia en la proliferación de su sitio web y en las actualizaciones de Google Search Index. Lo que estamos haciendo es pedir a Google que tome más tiempo para rastrear su sitio web, si se cambia la configuración para bajo.
Es importante señalar que estos ajustes < strong> sólo funcionan durante 90 días , después de ese tiempo, será dirigido automáticamente a la configuración predeterminada. Este cambio sólo cambia la velocidad de las solicitudes de Googlebot durante el proceso de rastreo. No tiene ningún efecto en la cantidad de veces que Google rastrea su sitio web o en cuán profundamente la estructura de URL es rastreada.
Fuente:https://blog.sucuri.net/



Entusiasta de la seguridad cibernética. Especialista en seguridad de la información, actualmente trabajando como especialista en infraestructura de riesgos e investigador.
Experiencia en procesos de riesgo y control, soporte de auditoría de seguridad, diseño y soporte de COB (continuidad del negocio), gestión de grupos de trabajo y estándares de seguridad de la información.
Envía tips de noticias a info@noticiasseguridad.com o www.instagram.com/iicsorg/.
También puedes encontrarnos en Telegram www.t.me/noticiasciberseguridad


